| 咨询电话:400-889-7783 | 中文 |English |
|
NVIDIA 产品
|
|
当今市场上数据中心 GPU 中的精尖之作
人工智能推理
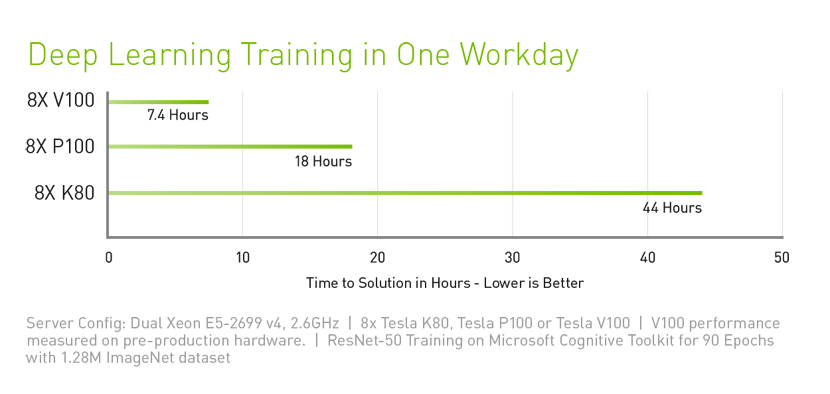
为了利用最相关的信息、服务和产品加强人与人之间的联系,超大规模计算公司已经开始采用人工智能。然而,及时满足用户需求是一项困难的挑战。例如,全球最大的超大规模计算公司最近估计,如果每个用户一天仅花费三分钟时间使用其语音识别服务,他们便需要将数据中心的容量翻倍。
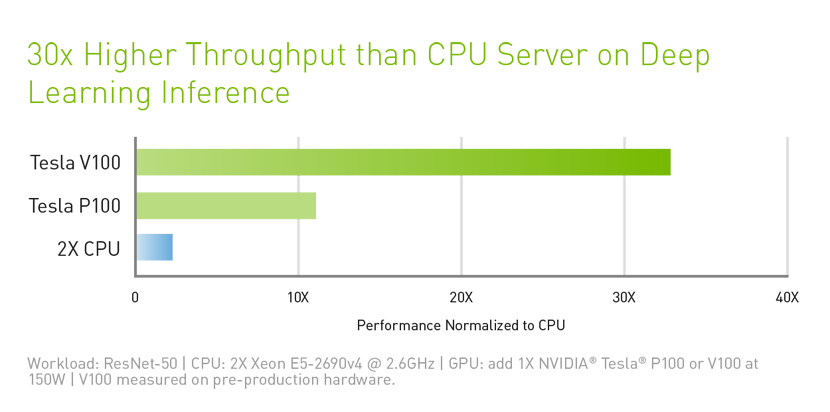
我们设计 Tesla V100 就是为了在现有的超大规模服务器机架上提供更高的性能。由于将人工智能作为核心,Tesla V100 GPU 可提供比 CPU 服务器高 30 倍的推理性能。这种吞吐量和效率的大幅提升将使人工智能服务的扩展变成现实。
高性能计算 (HPC)
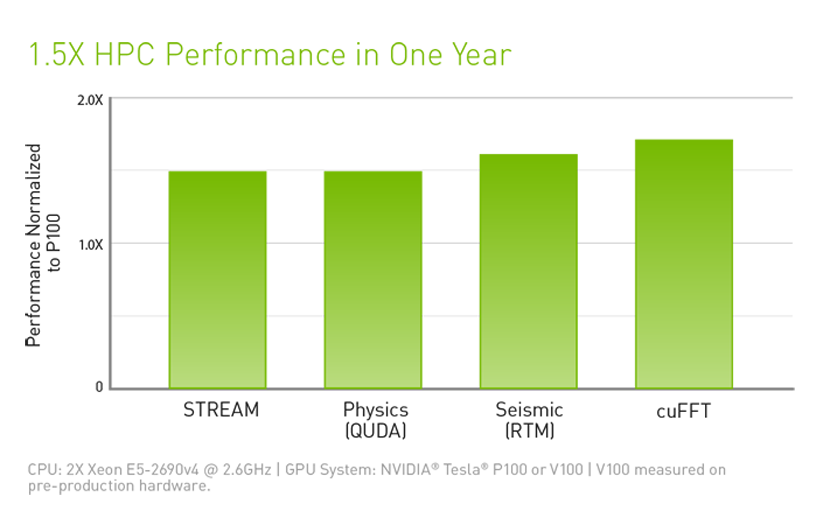
高性能计算是现代科学的基石。从天气预报到发现药物和发现新能源,研究人员使用大型计算系统来模拟和预测我们的世界。人工智能可让研究人员分析大量数据,在仅凭模拟无法完全预测真实世界的情况下快速获取见解,从而扩展了传统的高性能计算。
Tesla V100 的设计能够融合人工智能和高性能计算。它为高性能计算系统提供了一个平台,在用于科学模拟的计算机科学和用于在数据中发现见解的数据科学方面表现优异。通过在一个统一架构内搭配使用 NVIDIA CUDA® 内核和 Tensor 内核,配备 Tesla V100 GPU 的单台服务器可以取代数百台仅配备通用 CPU 的服务器来处理传统的高性能计算和人工智能工作负载。现在,每位研究人员和工程师都可以负担得起使用人工智能超级计算机处理最具挑战性工作的做法。
规格
|
|||||||||||||||||||||||||||||||||||||||||
服务器 |
NVIDIA产品 |
人工智能
|
主板
|
北京信维鑫玥科技有限公司
咨询电话:400-889-7783
|